Claudeと一緒にコードに住む
概要¶
この記事では以下の内容について扱います:
- AIモデルの能力を引き出すにはシステムが必要
- AIコーディングの記憶とシステムの問題点
- アクター(AIエージェント)が迷わずに行動できる環境(Niche)をどう作るかについて、ツールと仕組み
AIモデルの性能をシステムで引き出す¶
AIモデル(以下モデル)は優れた能力を持っていますが、一方で得意不得意があり、能力はジグザグ(Jagged)です。
そして、AIから実際に引き出せる性能はシステム(足場やハーネス)に依存することが様々な観点から言われています。
- Microsoft CEO Nadella argues AI’s real problem isn’t capability but that people haven’t learned to use it yet
- MicrosoftのCEOであるサティア・ナデラは、2026年をAIにとって重要な転換点と捉え、AIの普及が本格化する時期の始まりと位置付けている
- AIモデルは一般に考えられているよりもはるかに優れた能力を持っている
- 問題はまだ、それらをどのように活用すればよいのかが分かっていないことだと述べている
- AI Cybersecurity After Mythos: The Jagged Frontier
- 2026/4/7にAnthropicがMythosというモデルを提示した。セキュリティに関する能力が高いため、限定公開モデルとなった
- AISLEが同じ脆弱性を他のコストの低い小型モデルで検証したら大体再現できた
- また、ある脆弱性に対して完全に再現したモデルが、別の脆弱性に対しては失敗した。モデルの性能とセキュリティチェックの性能は比例しないとも
- AutoHarness
- 2026年3月のDeepMindの論文
- より小型のGemini-2.5-Flashモデルが、Gemini-2.5-Proのようなより大型のモデルよりも優れたパフォーマンスを発揮することを可能だった
- ハーネスをつけた下位モデルが上位モデルに勝った。また、ハーネスで作成したLLMなしのプログラムも上位モデルに勝った
- Gemini-2.5-Flashの敗北の78%は、ルール違反の操作によるものとされ、LLMがルールを理解していないことを示唆します
これは大量のファイルを扱うAIコーディングにおいても同様です。
LLMができる以前から機械的にコードを探索・解析・生成する方法は数多くあり、これらと生成AIを組み合わせることでモデルの能力はより必要な場所に集中して割り当てることが可能になります。
逆に言えば、AI提供サービスの不具合などでモデルの性能が劣化した場合でも、システムが十分に整っていれば、その性能差を意識しなくなるでしょう。
AIコーディングの問題点¶
前提として、AIコーディングにおけるAIエージェントはコードを探索・構築するアクターとします。
問題点1:記憶¶
現在のAIは「記憶」を持ちません。
学習済みのモデルが必要に応じて情報を取得し、都度「記憶」を再現します。
Contextual Agentic Memory is a Memo, Not True Memory は現状のAIの記憶分類を大きく二つ、モデルウェイトを変える θ と、コンテキストで注入する C として提示します。
この記事でもこの分類を用います。
ユーザー側ではモデルウェイトを変える θ の作業はできません。
毎回コンテキストで「記憶」を注入する必要があります。喩えるなら、AIエージェントはコルサコフ症候群のような健忘症にあると言えます。
つまり、AIコーディングはそれまでのコードの内容を把握していないAIに状況を把握させ、やるべきことを伝える作業が必要です。
問題点2:系の中にいると系が見えない¶
コンテキスト容量には限りがあります。
AIコーディングは多くの情報を扱う以上、大抵の場合、複数のエージェントを用いて実装を行います。
これは複数のAIエージェントからなる系(システム)と言っていいでしょう。
そのシステムがうまく動いたかというのは、内部の一エージェントからは判断がつきにくいです。
解決の方針¶
こうした問題に向き合う中で、「AIエージェントのためのNicheを作りたい」と考えるようになりました。
目指すのはAIエージェントが環境(コードリポジトリ)にアクセスしたら、自然と行動が促進されるような状況です。
手を動かした結果、後から以下の三つで整理できました:
- 機械で出せるものは機械で、推論は必要なところのみ
- エージェントの行動を固定する
- 複数エージェントの系を育てる
また、コンテキスト容量問題は以下のように、担当ごとのAIエージェント8個を作成し解決します。詳しい関係性は後に述べます。
- steward: ユーザーとやりとりする (orchestrator)
- surveyor: 地図を元に対象リポジトリの調査
- spec-critic: リポジトリのルール・目標などと仕様が一致するか確認
- corder: 無名のエージェント(general-purpose)
- critic: コードと仕様の乖離がないかレビュー
- concierge: ドキュメント担当
- tool-builder: 振り返りから必要なツール作る
- meta-retro: 複数セッション横断
機械で出す:決定的材料の生成¶
AIエージェントは非常に優れた能力を持ちますが、コストが掛かり行動には再現性がありません。
コードがシンプルであればエージェントが全て確認してもコンテキストに収まることもあるでしょう。
しかし、コードが大きく・複雑になると全てをエージェントが把握することは困難かつ冗長です。
コードの状態把握として必要なものは、大きく以下のように分類できるでしょう:
- コードの構造
- 歴史的経緯
- 要求・制約
任意の「作業に必要な情報」があるとして、本質的に解釈が必要なものは以上の三つを読み取った後になります。
それ以前の「何が作業に必要な情報か」は入力が確定すれば機械的に取得できることが大半です。
コードの構造を取得する・歴史的経緯を取得する:git-cartographer¶
大抵の場合、コードはGitで管理されます。
Gitを元にした解析方法として git churn や co-change があります。
私が作成しているOSS git-cartographer では、Git logを元に、リポジトリとコードの状態をjsonファイルとして出力します。
- Git logから
- hotspot: 最近変更が多いファイル一覧
- co-change: 同時に変更されることが多いファイル一覧
- stable: ほとんど変更のないファイル一覧
- AST symbol
- メソッドの位置、コールグラフの取得
jsonファイルから自動的にmarkdownファイルも生成可能で、人間にとっても可読性が上がります。
また、以上のデータを組み合わせることで、次の情報が分かります:
hotspotとco-change > 閾値以上→ 一緒に変わっているファイルがある、変更時は依存を確認stableとco-change = 0→ 孤立安定、削除は理由を確認
Claude Codeのhooksを使い、この情報をリポジトリにアクセスするエージェントに表示する機能を実装しています。
要求・制約を取得する:EARSカバレッジ¶
私は仕様をEARSで記載します。
EARSのメリットは、複数の要件を一ファイルにまとめられ、コード側に @see EARS-XXX#REQ-X-XXX といった表記で参照をコメントできることです。
こうすることで、仕様とコードが @see コメントによりリンクされているので、仕様のカバー範囲を把握しやすくなります。
また、EARS同士に関連する仕様が紐づけられていれば、先に示した spec-critic エージェントで要求の新規・更新作業の際に blast radius (要求の影響範囲)を把握することも可能です。
人間側認知とAIを紐付ける協働の仕組み¶
コーディングの大半はAIエージェントに任せるようになると、人間側の理解が追いつかない所謂「認知的負債」が発生します。
仕様は人間とAIで共同していたとしても、AIエージェントで実装するとどこまで終わったのか・何を確認したのか分からなくなりがちです。
実際にVerificationとValidationを取り違えやすく、AIが実装完了した→タスク完了≠動作する、ではないケースがありました。
そこで、 fsm-task-board というOSSを作成しました。
これは、 JSON Canvas を拡張したjsonファイルをレンダリング・編集するブラウザツールです。
各ノードにはverificationとvalidationのチェックボックスがそれぞれあり、タスクの管理に使えます。
古典的なタスク管理方法であるWBS/アロー図も考えましたが、問題は分解ではなかったので採用しませんでした。
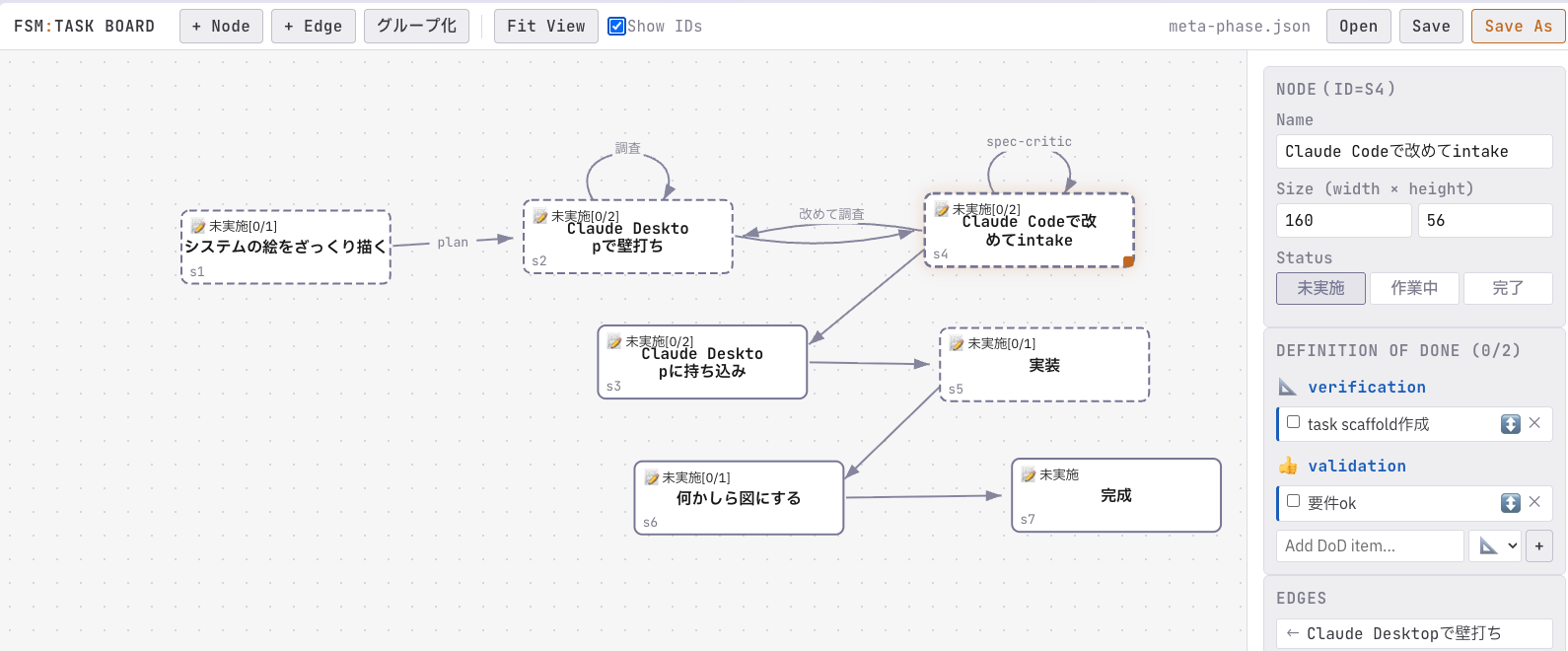
一方で、この図をClaudeと共有する場合にjsonファイルとスキーマを渡す必要があります。共有がとても面倒です。そのため、MCPを作成し、ClaudeにはMermaid.jsとして提示するようにしました。
これにより、仕様を決める前の壁打ちでキャンバスの内容をClaudeとやりとりする、タスクの状況をClaudeと共有するといったことがしやすくなりました。
stewardファミリー:組織に知性を宿す¶
各所で指摘されていることですが、現在のAIモデルにはsycophancyがあります。
そのため、作成したコードのチェックにはインスタンスが別のエージェントが必要です。
そのためのエージェントが critic と spec-critic です。
一体のエージェントではなく、複数のエージェントが決められた振る舞いを行い一つのタスクを実行します。
これはエンゲルバートの Augmenting Human Intellect #2c1e の相乗効果(synergism)を参考にしました。
graph LR
user["人間"]
subgraph code["対象リポジトリ"]
direction TB
surveyor["surveyor:
地図情報を元に解析"]
specCritic["spec-critic:
仕様が妥当かチェック"]
end
subgraph steward
direction TB
orchestrator1["steward"]
end
user -->|① タスク依頼| orchestrator1
orchestrator1 -->|② コード調査| surveyor
user <-->|③ 仕様決定| orchestrator1
orchestrator1 -->|④ 仕様レビュー| specCritic
specCritic -->|⑤ 差し戻し| orchestrator1
graph LR
user["人間"]
subgraph code["対象リポジトリ"]
direction TB
corder["corder:
実装"]
critic["critic:
レビュー"]
end
subgraph steward
direction TB
orchestrator2["steward"]
subgraph sessionRetro["実装後振り返り"]
toolBuilder["tool-builder:
steward側自動化"]
end
end
user -->|① 仕様書提示・実装依頼| orchestrator2
orchestrator2 -->|② 実装指示| corder
orchestrator2 -->|③ レビュー依頼| critic
critic -->|④ 差し戻し| orchestrator2
orchestrator2 -->|⑤ 振り返り: sessionRetro| orchestrator2
orchestrator2 -->|⑥ 自動化| toolBuilder
また、一回のタスクだけでは全体としてのシステムが分からないこともあるため、タスクの情報や各種エージェントの出力をファイルに記録し、一定期間を置いて(例えば一週間に一回) meta-retro エージェントに解析させます。
これは同様にエンゲルバートのABCモデル(A=本業、B=本業を改善する活動、C=改善活動自体を改善する活動)のCにあたります。
graph TB
user["人間"]
subgraph steward
direction TB
orchestrator3["steward"]
metaRetro["meta-retro"]
concierge
end
user -->|① meta-augment依頼| orchestrator3
orchestrator3 -->|② 横断振り返り| metaRetro
orchestrator3 -->|③ ルールとツール追加・削除検討| user
orchestrator3 -->|④ ルール追加先確認| concierge
spec-critic・critic・session-retro・meta-retroは系の外から系を観察する装置です。
- spec-critic: ユーザーとstewardによる仕様の合意という閉じた系を観察
- critic: コーディングという閉じた系を観察
- session-retro: セッションという閉じた系を観察(orchestratorが観察するためsycophancyが強め)
- meta-retro: stewardシステムという閉じた系を観察
ただし、 session-retro と meta-retro は観察に留まりません。観察結果はルールとツールへと収穫され、系そのものを書き換えます。
これらはエージェントが住む環境(リポジトリ)を能動的に作り変える Niche 構築であり、最初に欲しかった「アクターのためのNiche」は、この還流ループの中で育っていきます。
そして観察とツール化が積み重なるほど、モデルの θ にはないユーザー側の経験が環境( C 側)に蓄積します。
個々のエージェントのモデルが入れ替わっても系の性能が維持しやすくなります。
組織が自らを観察し作り変えるこの仕組みによって、AIモデルの性能を必要な部分に効率的に引き出すことができます。